マイコンで実現するフィードバック制御のための基礎知識【発展編】

マイコンで実現するフィードバック制御のための基礎知識【応用編 】では古典制御理論をベースに実践で使われるPID制御を解説しました。PID制御は感覚的にゲインを設定できるので、制御をするモデルが比較的単純なものである場合は現場でも使いやすいのですが、外乱や制御対象のパラメータ変動などによりモデル化できなかった部分の影響が大きい場合は望んだとおりの性能は期待できないことになります。
そこで、本編では従来の古典制御理論を発展させたDCモータを制御モデルとしたアドバンスト制御とよばれるものを紹介します。目的は実践で使うには避けられないモデル化の誤差や負荷の変動といった外乱がある場合にも本来想定したとおりの性能をだすことです。
アドバンスト制御といえば、代表的なものにロバスト制御や適応制御などがありますが本来理論中心の難解な解説が多くて敷居が高く学術的で、一般用途には無縁のものに思われますが、ここでは実践ですぐにも使えそうなものを紹介し、誰でも利用できそうな実用的なものを解説していきます。
目次
モデル誤差や外乱に強いロバスト制御

アドバンスト制御のなかでも、本編ではロバスト制御を解説していきます。
ロバスト制御というものはDCモータなどの物理的な制御モデルを数式化した際のモデル化誤差や負荷変動などの制御対象P(s)の入力側に加わる外乱、およびセンサノイズなど制御対象の出力側に加わる外乱に対して制御出力が影響を受けにくい制御システムのことをいいます。
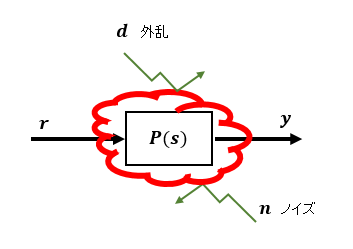
ロバスト制御では、端的にいうと外乱d、観測ノイズn、および多少のモデル誤差化⊿があっても入力rから出力yまでの伝達関数 Gry(s) が設定した特性(例えば時定数Trの1次遅れ)になるように補償器C(s)を設計します。
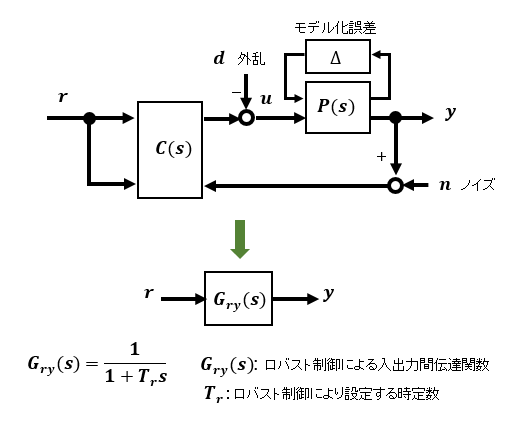
ロバスト制御のうちでも、PID制御なみに簡易に実現できるものであれば、ちょっとしたアプリケーションにも積極的に適用したいものです。本編ではそんな比較的気楽に扱えるような実用的なものの検証をしていきたいと思います。
2自由度制御システム
従来のPID制御はフィードバックループ内にあるPID補償器の比例・積分・微分ゲインをそれぞれ設定して出力を調整するものです。各ゲインの決め方は経験に基づいた値を試行錯誤的に決めることも多いようです。
PID制御の利点は理論的なものを理解していなくても手軽に感覚的に設定できることですが、ゲインにより調整できるのは応答性であって、外乱などに対しては特性の根本的な改善はできません。
また、PID制御を始めとする従来のフィードバック制御ではループ内のゲインを上げる(増幅)ことによって、安定性や応答性を改善することはできますが、同時にモデル化誤差やノイズなど望まないものも増幅してしまうことにより想定したとおりの性能がだせない場合も起こりえます。単なるフィードバック制御では精度や応答性の向上を望むには限界があるといえます。
そこで、ロバスト制御を実現するのにあたって応答特性と外乱抑制を独立して設定できる2自由度制御システムと呼ばれる制御方法があります。ロバスト制御には他に外乱やモデル化誤差を推定して変化分をキャンセルする外乱オブザーバー的な方法もありますが、本編では2自由度制御を取り扱います。
2自由度制御にもいろいろありますが、今回取り扱うものは、最もシンプルで誰でも検証しやすく、プログラミングなどでも実現しやすいものです。
入力rから出力yまでのブロック線図は下図の形になります。通常のフィードバック制御用ループに加えて入力から分岐した情報を加えた形になっています。
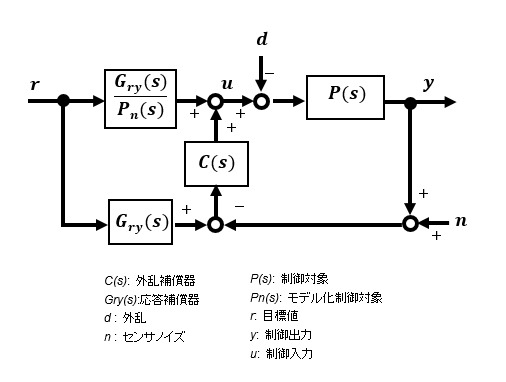
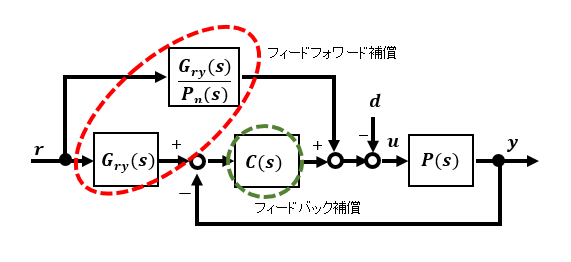
上のブロック線図の配置を並べ替えると下図のような等価ブロック線図となります。これが意味しているところはフィードバック部とフィードフォワード部で構成されていて、外乱抑制はフィードバック補償器C(s)、応答特性はフィードフォワード部のGry(s)およびPn(s)で改善します。これらが干渉することなく独立して設定できることから2自由度と呼ばれています。
ロバスト制御で扱う近似モデル
マイコンで実現するフィードバック制御のための基礎知識【応用編 】ではDCモータの特性についてモータ回転速度は入力電圧を変化させれば調整できることを説明しました。無負荷であれば回転速度は入力電圧にほぼ比例していますので入力をu、出力をyとすると下図のような1次遅れで近似モデル化できます。
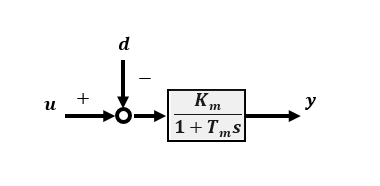
近似モデルゲインKm、時定数Tmは実際の入力を与えたときの回転速度yを実測して得られるものに相当します。これは一種のパラメータ同定と呼ばれますが、DCモータの実際の慣性モーメントJや粘性摩擦Dといった物理的なパラメータでなく近似モデルのパラメータです。
入力uから出力yまでの物理的パラメータが KmとTmに集約されていてより実用的なモデルです。 入力は電圧でも電流でもよく、パラメータ KmとTm はそれに応じた値になります。 Km は伝達関数のゲインなのですが、入力から出力までの変換係数といった捉え方がわかりやすいのではないでしょうか。
制御の用途にもよりますが、物理的モデルを数式化するときに正確を求めて詳細にすぎてもあまり意味がなく実用的でありません。パラメータは変動するものですし、外乱は常に存在するものです。数式モデルがあっての制御ですので最低限の特性を抑えたモデルは必要ですが、ロバスト制御の場合は特に制御対象のモデルは簡素化したものでよいのではないでしょうか。
モデル化誤差や外乱があっても安定した速度制御
DCモータを制御対象にした2自由度制御システムによる速度制御を解説します。
制御対象P(s)には入力uを電圧または電流、出力yをモータ回転速度とした1次遅れモデルとします。この実モデルは変動の可能性があるパラメータKm, Tm を持ちますが、この規範モデルをPn(s)とします。
規範モデルPn(s) のパラメータは実モデルP(s)のパラメータ同定により得られたパラメータKm,Tmをそれぞれ規範モデルパラメータ Kn,Tn とし、フィードフォワード補償器内で使用するものです。
フィードフォワード補償部は特性改善後の入出力間目標応答特性Gry(s)および規範モデルの逆システムPn (s) -1 で構成され、フィードバック補償部には、ロバスト特性を決定するゲインC(制御対象により今回は定数)が入ります。
特性改善後の入出力間目標応答特性Gry(s)は時定数Tm2の1次遅れとしますが、時定数Tm2は実現できるレベルで設定する必要はあります。

制御対象P(s)にモデル化誤差がない場合の応答特性:
制御対象の実モデルP(s)と規範モデルPn(s)に誤差変動がなく P(s) = Pn(s) である場合、入力rから出力yまでの伝達関数は設定した目標応答特性Gry(s) となります。
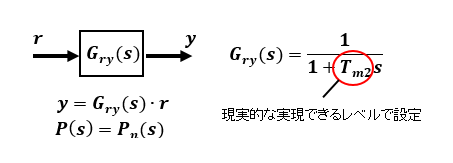
制御対象P(s)にモデル化誤差がある場合の応答特性:
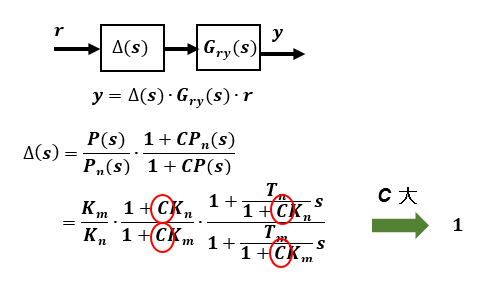
制御対象の実モデルP(s)と規範モデルPn(s)に誤差変動がある場合、下図の⊿(s)が変動分です。フィードバックゲインCが大きいほど変動誤差の影響は小さくなるので 設定した目標応答特性Gry(s) に近づきます。
今回設定したフィードフォワード補償のタイプでは変動があっても、実モデルパラメータと規範モデルパラメータが互いに相殺しあうかたちになっているのも特徴です。
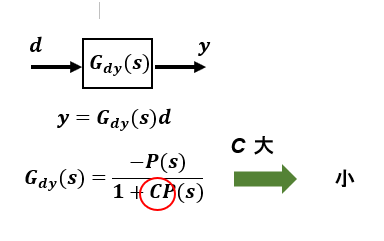
外乱に対する出力への影響:
ここが、2自由度ロバスト制御の本質的な部分です。外乱特性はフィードバックゲインCにのみ関連していて応答特性を決定する 目標応答特性Gry(s) とは無関係です。
ゲインCが大きくなるほど出力への影響は小さくなることがわかります。この値も実現可能な範囲で設定します。
定常偏差をなくす場合:
今回の2自由度制御では 目標応答特性Gry(s) を1次遅れとしているため、負荷トルクが定常負荷のように一定で大きい場合は、定常誤差が発生してしまいます。この誤差を小さくするためにはフィードバックゲインCを大きくすると零に近づきますが収束するわけではありません。
どうしても、出力を目標値に一致させるためには外側に定常偏差をなくすためのPIフィードバック補償ループを追加して適当な比例、積分ゲインを調整します。
実装のポイントはロバスト制御部をできるだけ高速で処理し、PIフィードバックによるサーボ補償のループをそれよりも遅い処理にして相互干渉による影響をなくすことです。

速度制御であればロバスト補償ゲインCで外乱の影響はほぼ受けなくなるので、負荷にかかわらず一定速度を精度よく保つ用途でもなければあえて定常偏差をなくすためにPI制御ループを付加する意味はあまりないかもしれません。
シミュレーションによる検証(2自由度ロバスト制御)
DCモータ開ループ状態で出力応答:
検証した結果の時間応答をシミュレーション( Scilabを使用 )して確認します。
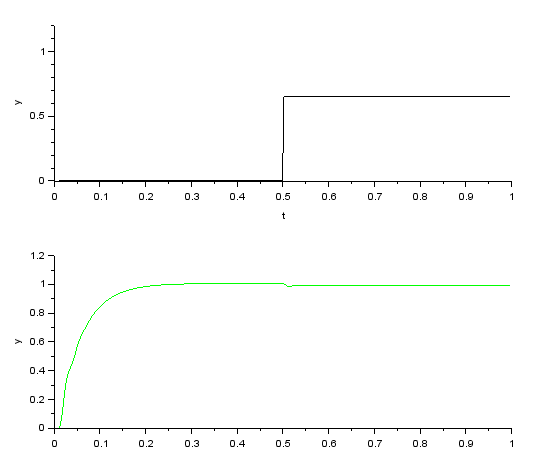
DCモータに開ループ状態でステップ入力時にパルス状の負荷外乱を与えたときの応答です。ちょっとしたパルス状の負荷でも出力に大きな影響を与えることがわかります。
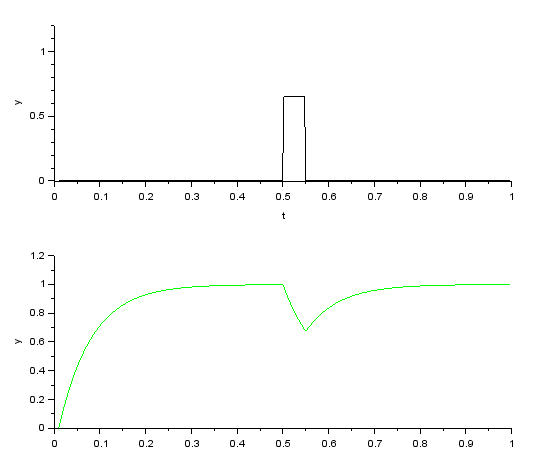
今度はステップ状の負荷外乱を与えたときの応答です。 指令値から大きく下がったところで負荷に応じて発生トルクと釣り合ってしまっています。
2自由度ロバスト制御 出力応答 :
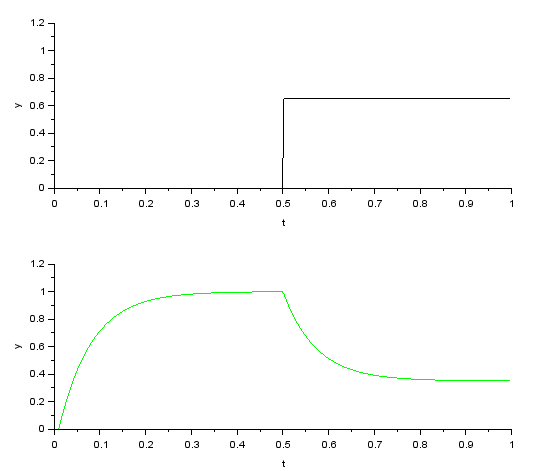
目標応答特性Gry(s) の時定数Tm2を50ms、ロバスト補償器ゲインCを0.5とした条件でパルス状外乱を与えたときの出力応答です。制御対象には、規範モデルに対してKmは+30%、Tmは-20%の モデル誤差に加えて、時定数10msの1次遅れ寄生要素を追加しているので2次遅れ系となっていますが、多少のモデル化誤差では出力は 目標応答特性Gry(s)の特性を維持したまま、外乱を短期間で抑制しているのがわかります。
ロバスト補償器ゲインCを更に大きくすると外乱やモデル化誤差の変動の抑制効果は向上します。
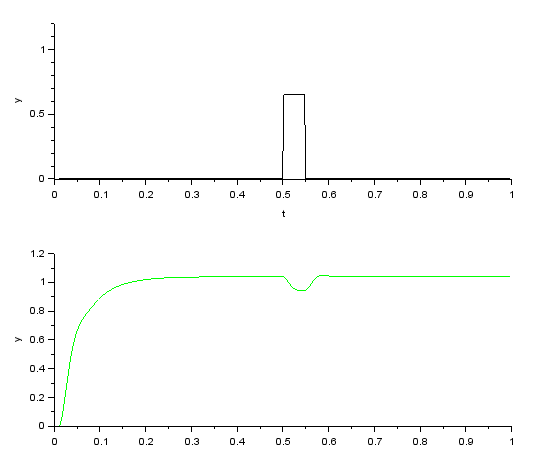
ロバスト補償器ゲインC だけを3に増加してから外乱をステップ負荷としたときの応答です。ここでも 出力は 目標応答特性Gry(s)の特性を維持したまま、外乱の影響が出力にほぼ現れず、ロバスト制御の効果が見られます。応答特性と外乱抑制特性を独立して設定できる2自由度制御の効果をよく表しています。
ハイゲインフィードバック方式との比較
簡易的な速度制御特性を改善する方式にハイゲインフィードバック方式があります。出力側をゲインC1を介してフィードバックし、 ゲインC1とC2の値を組み合わせて外乱を抑制しながら入出力間のゲインを1に近づけことができるとても簡単な方式です。
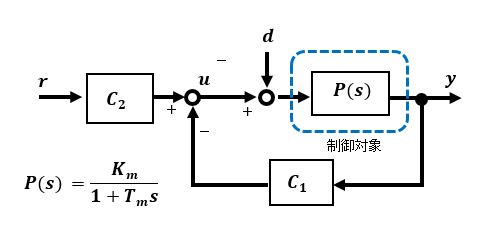
外乱特性を向上するためには 外乱抑制用フィードバックゲインC1を上げれば改善できます。C1の大きさに頼るところからハイゲインフィードバックと呼ばれます。

応答特性は全体のゲインが1になるようにC2により調整することで求められますが、外乱抑制用ゲインC1の大きさに依存するうえに、任意の応答特性を得ることはできません。また、外乱を抑えるためのハイゲインに頼ることになるため、出力側センサーからのノイズの影響を受けないように注意する必要があります。
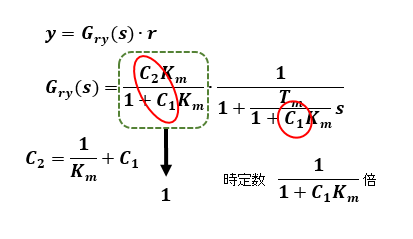
ロバスト制御まで必要としない比較的外乱の影響が小さい用途では気軽に実現できるハイゲインフィードバックは有用です。アプリケーションに応じて使い分けるとよいでしょう。
シミュレーションによる検証(ハイゲインフィードバック)
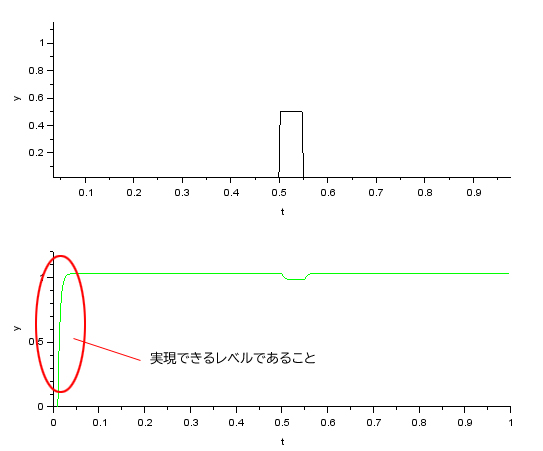
パルス状の 外乱負荷として加えたときの応答をシミュレーション結果です。外乱パルスはフィードバックゲインC1により抑制されていますが同時に応答も影響をうけてゲインやモデル化パラメータによっては過応答になってしまいます。
外乱抑制と応答特性はフィードバックゲインC1により決定づけられてしまいますが、実現できる範囲で設定できるようであればハイゲインフィードバック方式は最も簡単で実用的です。
位置決め追従制御(加速度指令方式)
速度制御モデルが外乱やモデル化誤差の影響を受けない目標応答特性Gry(s)でモデル化されていると簡単に位置決め追従制御に発展できます。ここでは、産業用途ではよく目にする速度制御用フィードバックループの外側に位置制御用フィードバックループで構成されているタイプとは異なる、加速度指令方式位置決め追従制御を解説します。
速度応答が外乱やモデル化誤差の影響をうけない目標応答特性Gry(s) である場合、速度の微分である加速度を指令とした場合、入力から出力までの伝達関数は目標応答特性Gry(s)を積分したものになります。

応答 Gry(s)の時定数Tm2は実現できる範囲で十分小さく設定することが好ましいです。
加速度指令値を生成するために予め位置θ0、速度θ'0、加速度 θ"0 の追従軌道の目標値を作成しておきます。加速度参照値θ"0をフィードフォワード項として、速度θ'0、位置θ0参照値と実際値 θ, θ' との誤差にそれぞれゲインKv, Kpをかけたものをフィードバック項として加速度指令値 θ"refとします。
ゲインKvとKpは 2次遅れ系の応答を参考にして目標の速応性および減衰性を考慮して簡単に決定できます。設定した2次遅れ系の応答で起動時の誤差が収束すると⊿θ(=θ0-θ)は0、つまり実際位置θは遅れなく参照値θ0に追従することになります。

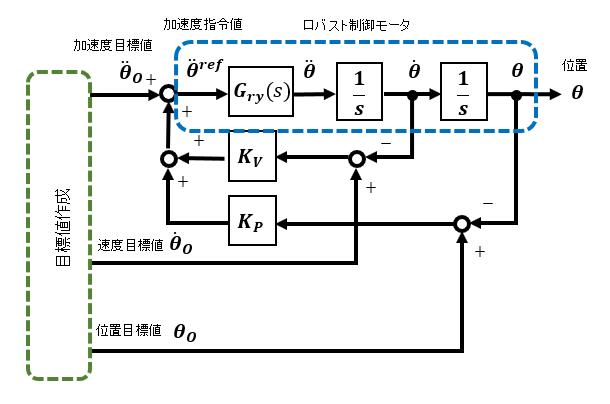
上式が成立するのは速度系にロバスト制御が施されていて速度指令値θ'ref ≒ 速度θ' となることにより加速度指令値θ"ref ≒ 加速度θ" とみなせるからです。
上式だけ見ているとゲインKV、KPは任意に決めても問題なさそうですが ゲイン選定を適当にすると応答は乱れる可能性があります。 これらのゲインで2次遅れ系規範モデルを構成することになるからです。
位置決めサーボ系として見た場合、指令値に目標位置θoのみ与えた場合は目標値θoから出力θまでの伝達関数は2次遅れ系の規範モデルKP/(s2+KVs+KP)となり、出力θは遅れて追従します。
規範モデルに対して指令値に加速度θ"oおよび速度θ'oを含めることにより、それらが位置決めサーボ系ではフィードフォワード的な役割を果たし、出力θは定常偏差がなくなり目標値θoに遅れなしに追従するようになるのです。見方を変えると規範モデルの逆システムを構成するのと等価になります。
つまり、システムとしては規範モデルが安定であることが必要で、仮に不安定な極をもつ規範モデルに対して、不安定な零点をもつ規範モデルの逆システムを構成すると、数式上では相殺されるので問題がなさそうですが、実際は必ず遅れ要素やモデル化誤差および外乱等が存在するため、相殺されることはなく不安定なままであるということです。
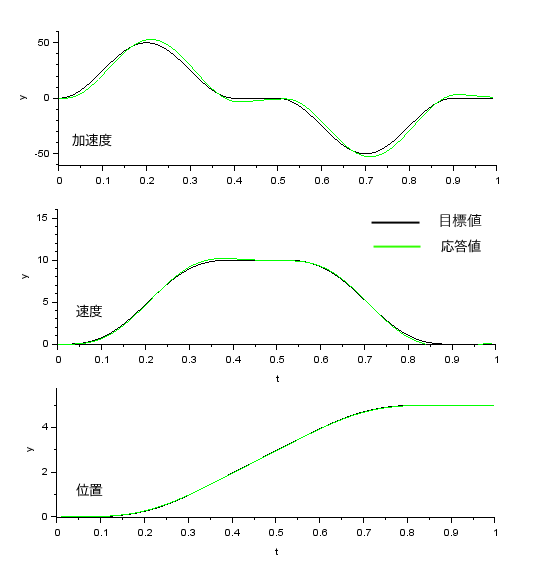
シミュレーションによる検証(位置決め追従制御)
速度系目標応答特性Gry(s) の時定数Tm2を10ms、ゲインKvとKpは 速応性ωn=10,減衰 0.8としてKv=16, Kp=100 としたときの追従性をシミュレーションしてみました。比較的緩やかな目標値の場合ですので時定数が大きめでも位置は遅れなく追従できていることが確認できます。
制御のなかでも、ロバスト制御は高度な分類のもので一般・趣味用途では無縁であったものかもしれませんが、今回紹介したものではちょっとしたマイコンを使ったプログラムによるモータコントロールなどには簡単に応用できるのではないでしょうか。
通常、電圧入力のDCモータコントロールはエンコーダなどからフィードバック制御を行っても、PID制御であれば特性改善はそんなに望めませんが、本編の2自由度ロバスト制御やハイゲインフィードバックを施せば外乱の影響を抑制できるために、ステッピングモータのような感覚でモータを扱えるようになるので用途が広がります。
シミュレーションによる検証は入力に制限のない条件で行っています。実装の際にはモータ端子電圧や最大電流などで制約されますので実現できるかどうかは物理モデルの条件を入れて確認する必要があります。次回は実機で検証を行っていきたいと思います。


